Neural Video Coding using Multiscale Motion Compensation and Spatiotemporal Context Model
Introduction
We propose an end-to-end deep neural video coding framework (NVC), which uses variational autoencoders (VAEs) with joint spatial and temporal prior aggregation (PA) to exploit the correlations in intra-frame pixels, inter-frame motions and inter-frame compensation residuals, respectively. Novel features of NVC include: 1) To estimate and compensate motion over a large range of magnitudes, we propose an unsupervised multiscale motion compensation network (MS-MCN) together with a pyramid decoder in the VAE for coding motion features that generates multiscale flow fields, 2) we design a novel adaptive spatiotemporal context model for efficient entropy coding for motion information, 3) we adopt nonlocal attention modules (NLAM) at the bottlenecks of the VAEs for implicit adaptive feature extraction and activation, leveraging its high transformation capacity and unequal weighting with joint global and local information, and 4) we introduce multi-module optimization and a multi-frame training strategy to minimize the temporal error propagation among P-frames. NVC is evaluated for the low-delay causal settings and compared with H.265/HEVC, H.264/AVC and the other learnt video compression methods following the common test conditions, demonstrating consistent gains across all popular test sequences for both PSNR and MS-SSIM distortion metrics.
Architecture
Our NVC framework is designed for low-delay applications.As with all modern video encoders, the proposed NVC com-presses the first frame in each group of pictures as an intra-frame using a VAE based compression engine (neuro-Intra). Itcodes remaining frames using motion compensated prediction. It uses the VAE compressor (neuro-Motion) to generate the multiscale motion field between thecurrent frame and the reference frame. Then, MS-MCN takesmultiscale compressed flows, warps the multiscale features ofthe reference frame, and combines these warped features togenerate the predicted frame. The prediction residual is thencoded using another VAE-based compressor (neuro-Res).
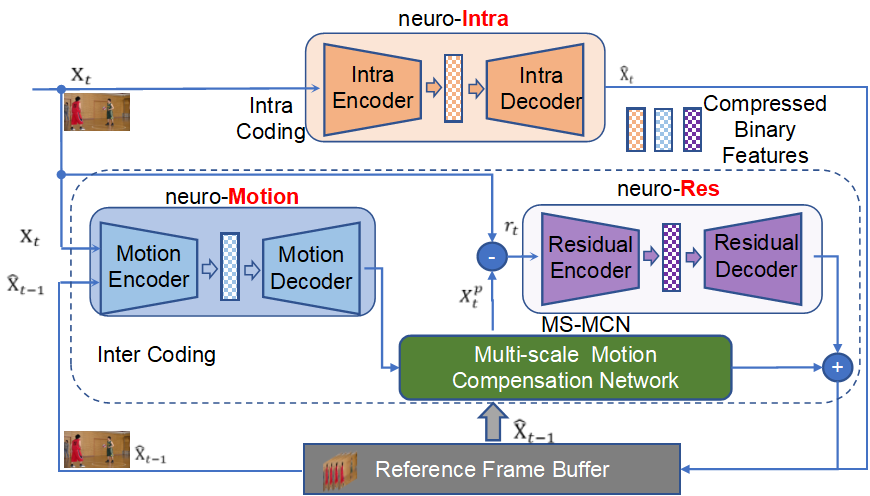
Variational Autoencoder with (Spatiotemporal and hyper) Prior Aggregation (PA) Engine
The general architecture of the avriational autoencoder VAE with prior aggregation. Here, the PA engine aggergates spatiotemporal and hyper prior based on Gaussian distribution for entropy coding.
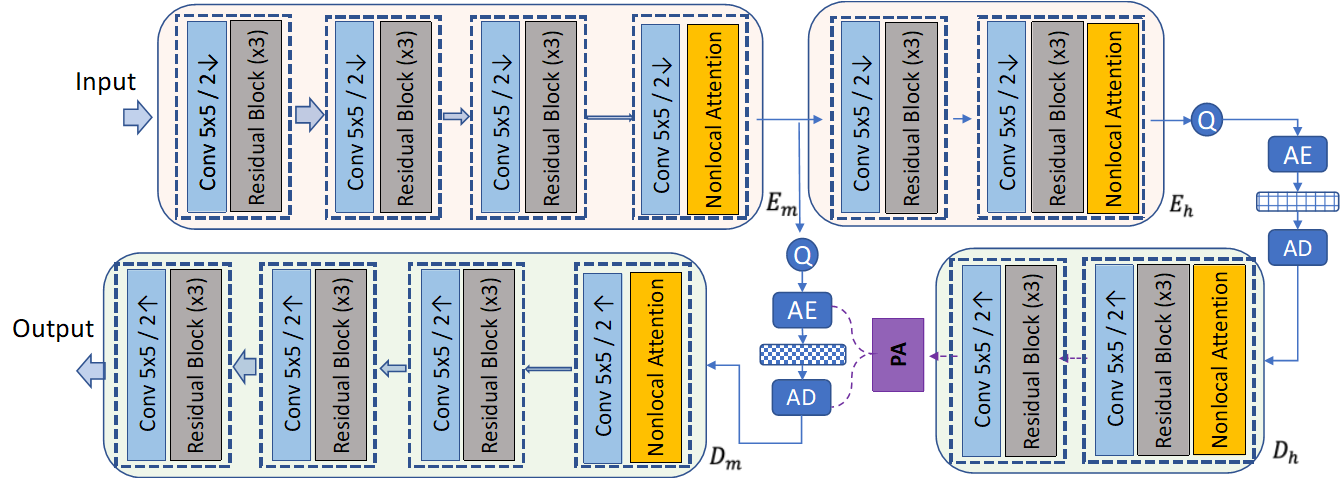
Pyramid Decoder and Multiscale Motion Compensation
We apply the pyramid flow decoder in the neuro-Motion and generate the multiscale compressed flows. Then we use multiscale motion compensation (coarse-to-fine warping both in feature and pixel domain) to obtain the predicted frame.
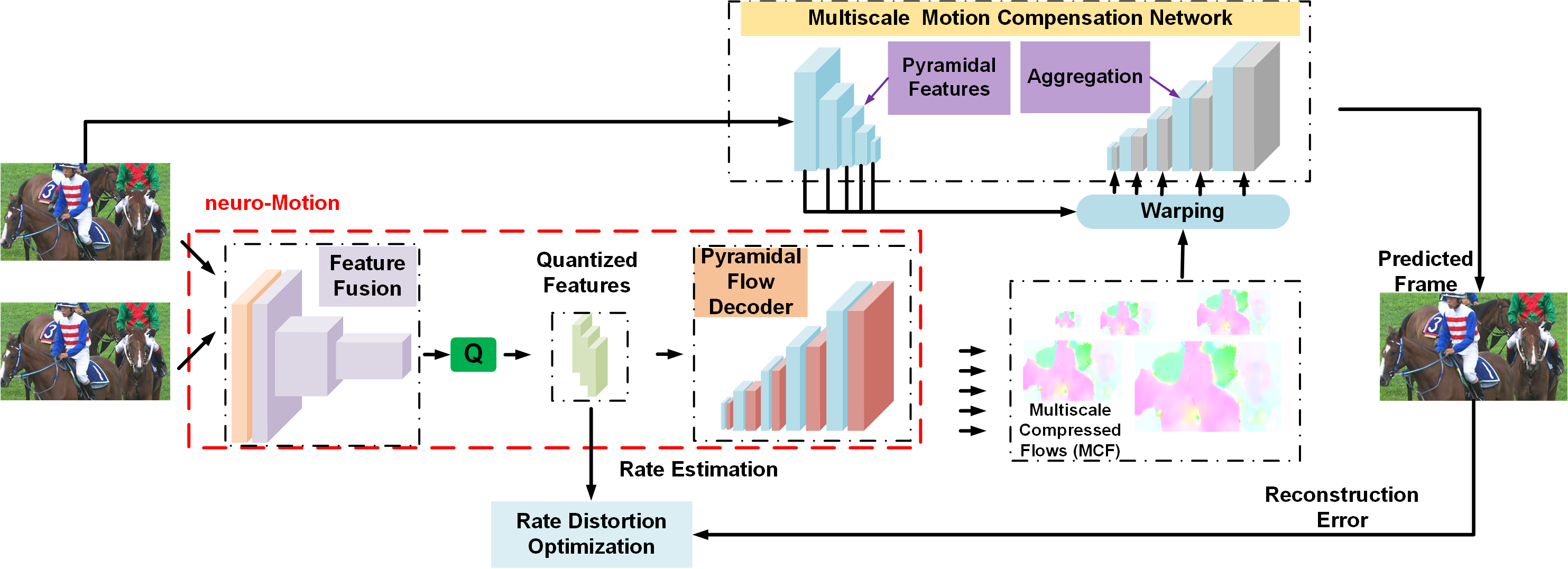
Adaptive Spatiotemporal Context Modeling for Entropy Coding
The proposed PA engine for neuro-Motion consists of a spatio-temporal-hyper aggregation module (STHAM) and a it temporal updating module (TUM). At timestamp $t$, STHAM accumulates all the accessible priors and estimate the mean and standard deviation of the assumed Gaussian distribution for each new quantized motion feature. To generate the temporal priors, TUM is applied to current quantized features recurrently using a standard ConvLSTM.
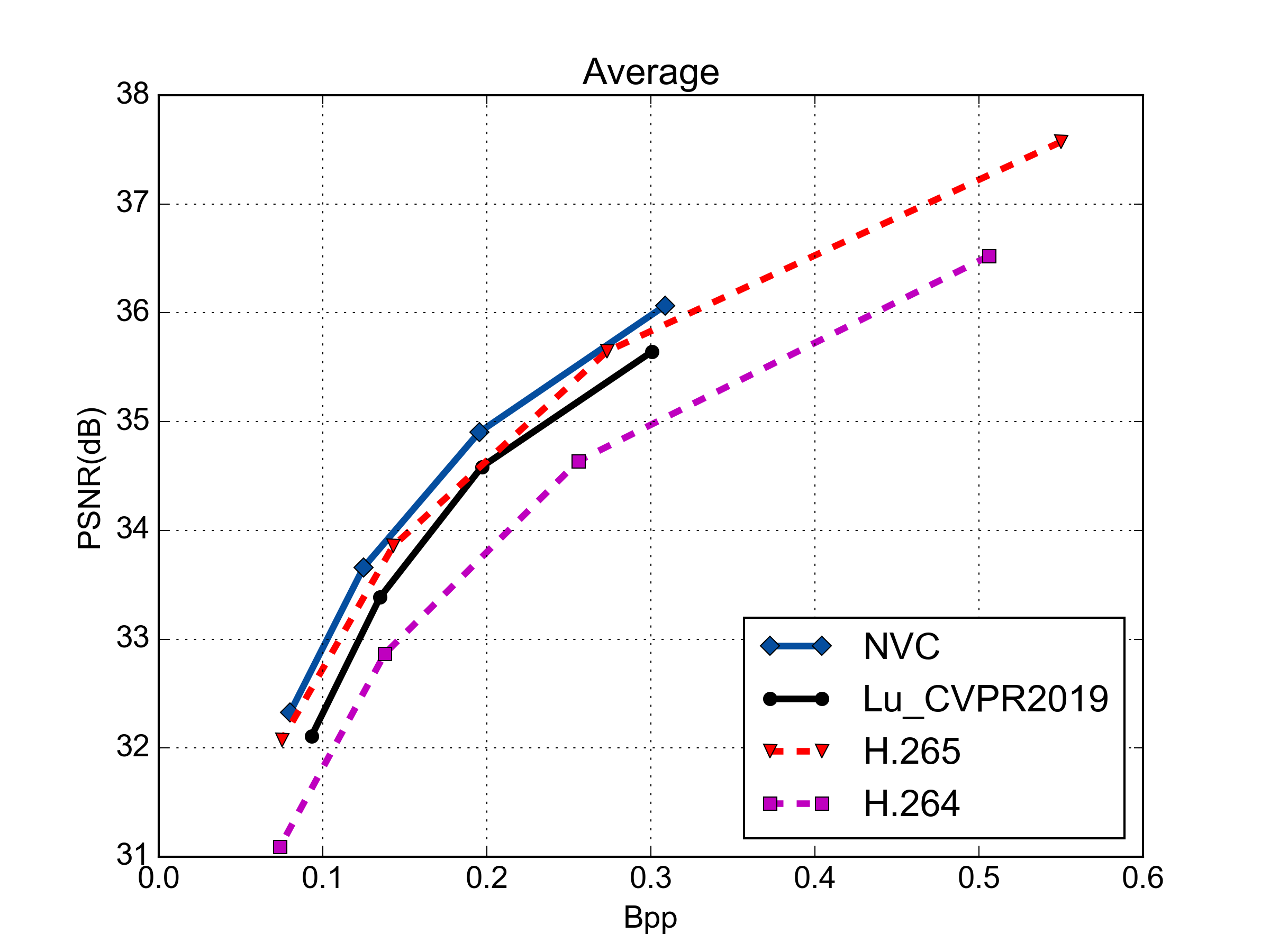
Rate-Distortion Performance (PSNR & MS-SSIM)
PSNR vs. Rate Performance
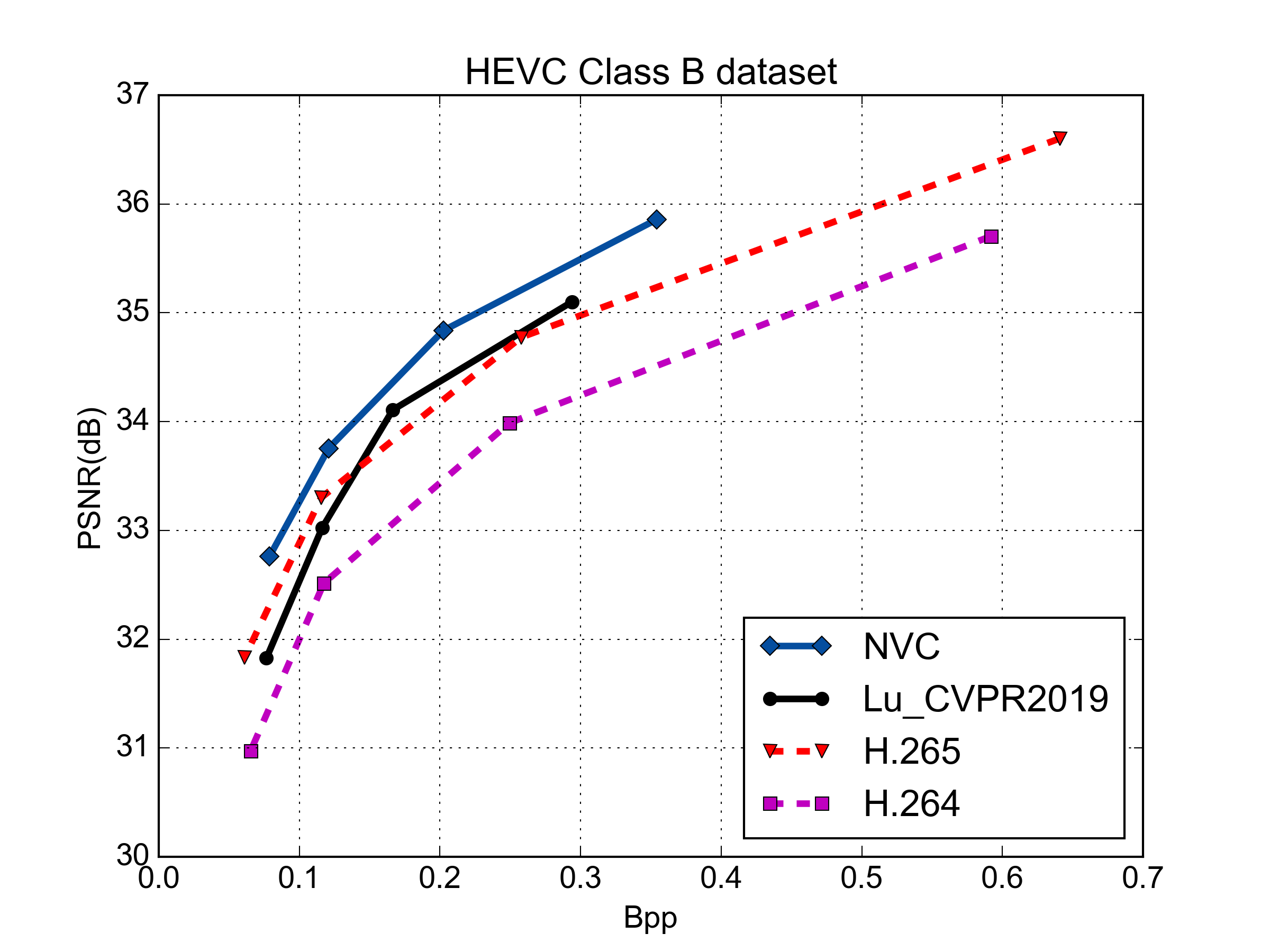
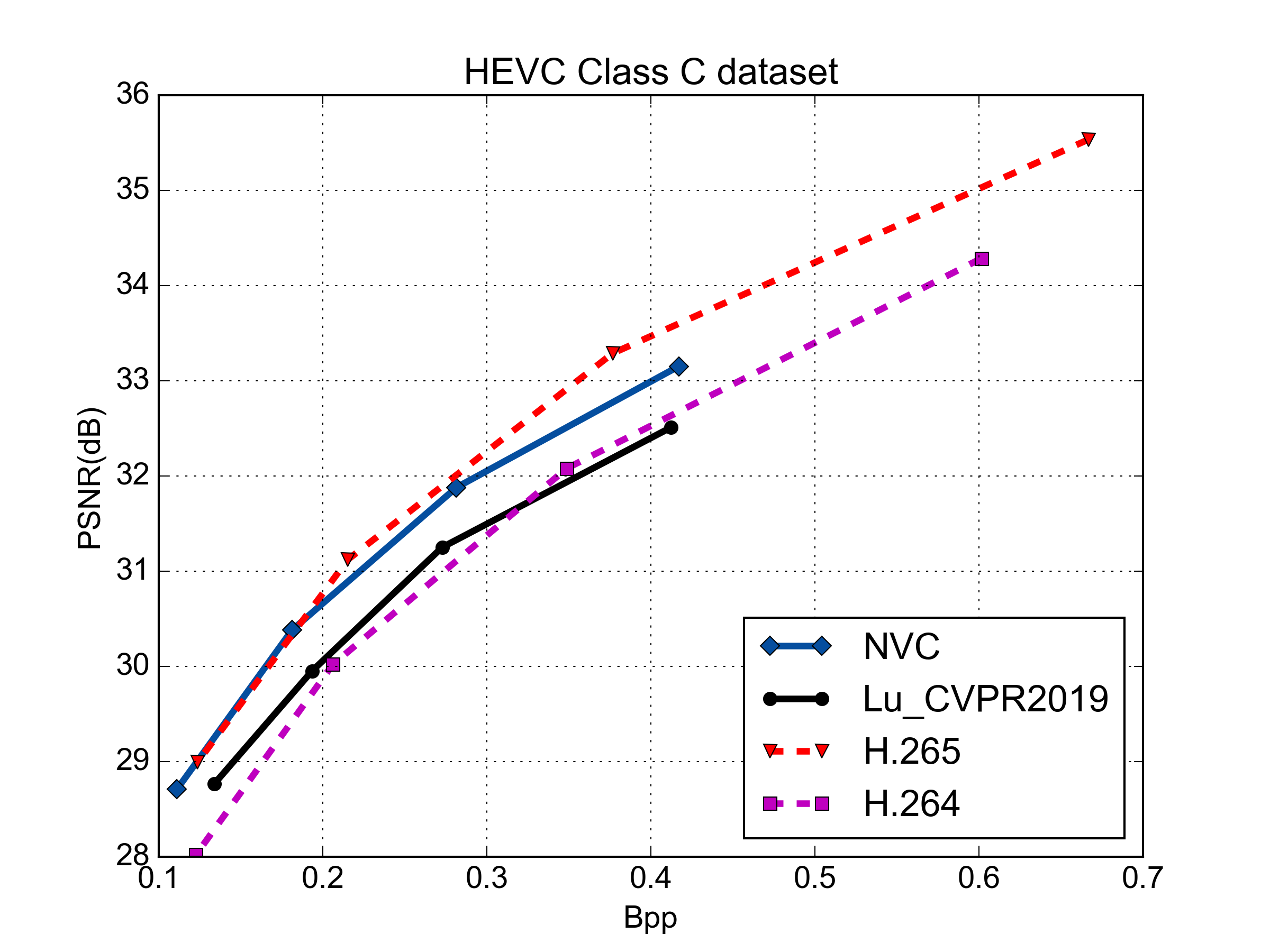
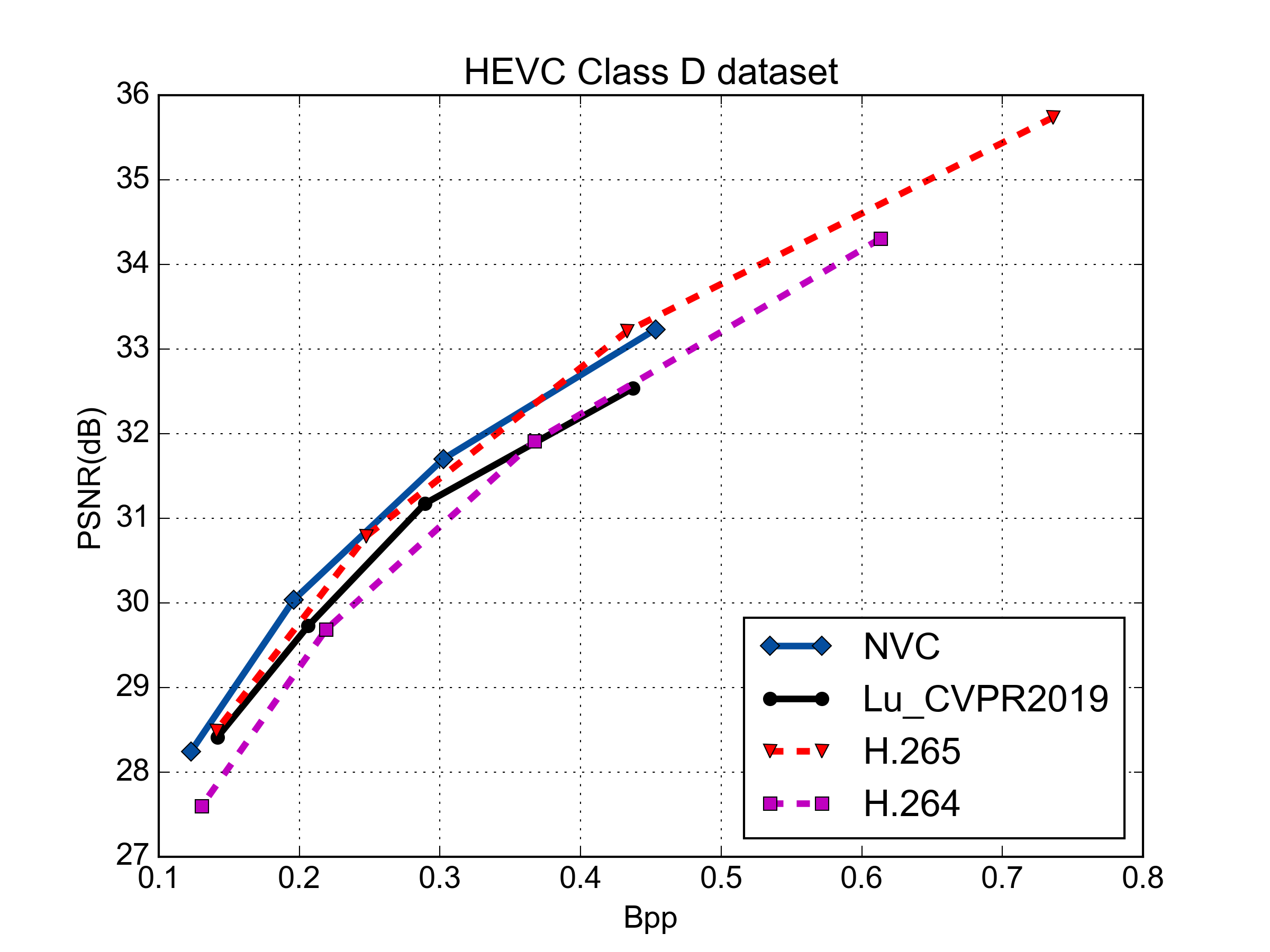
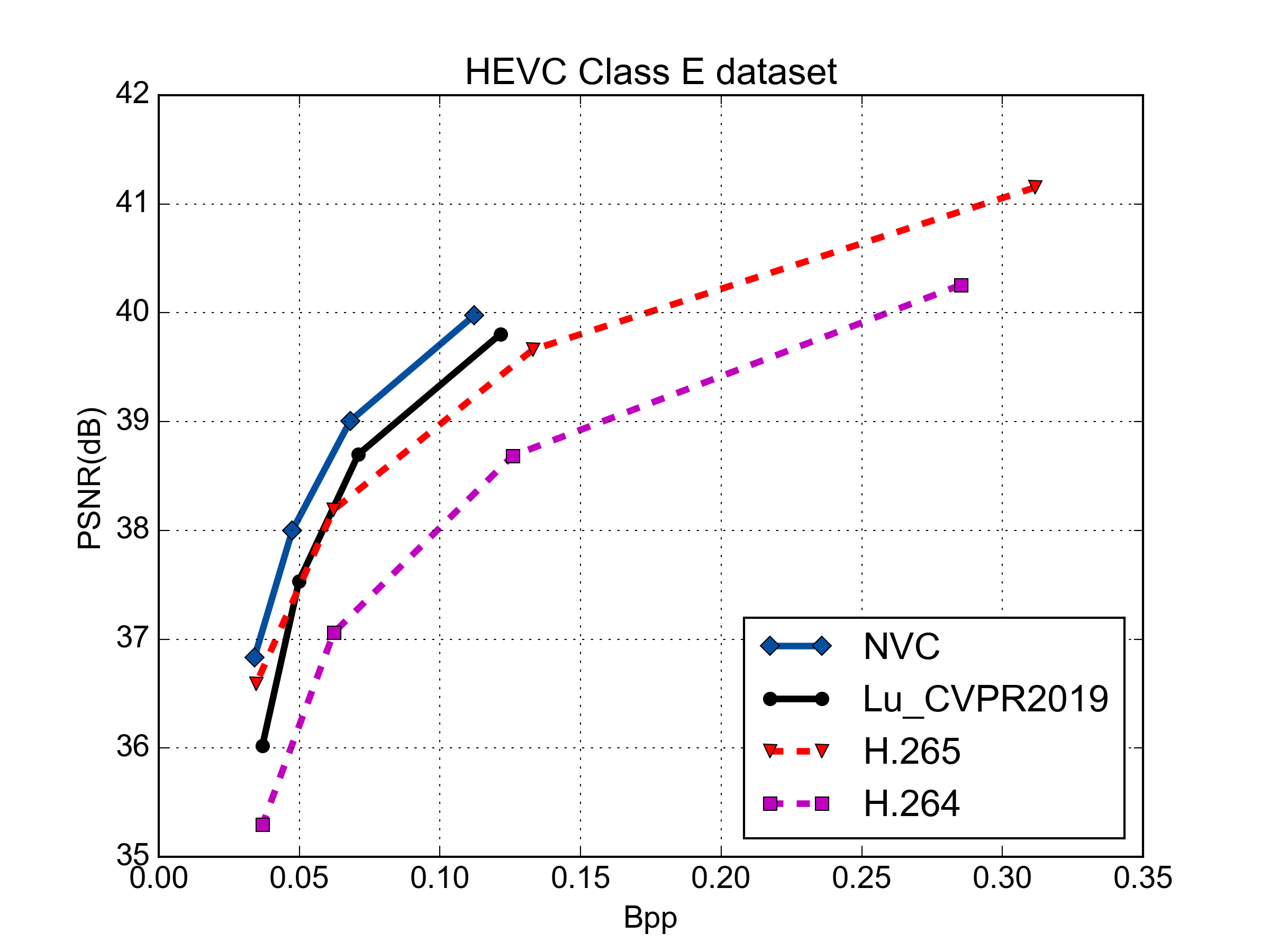

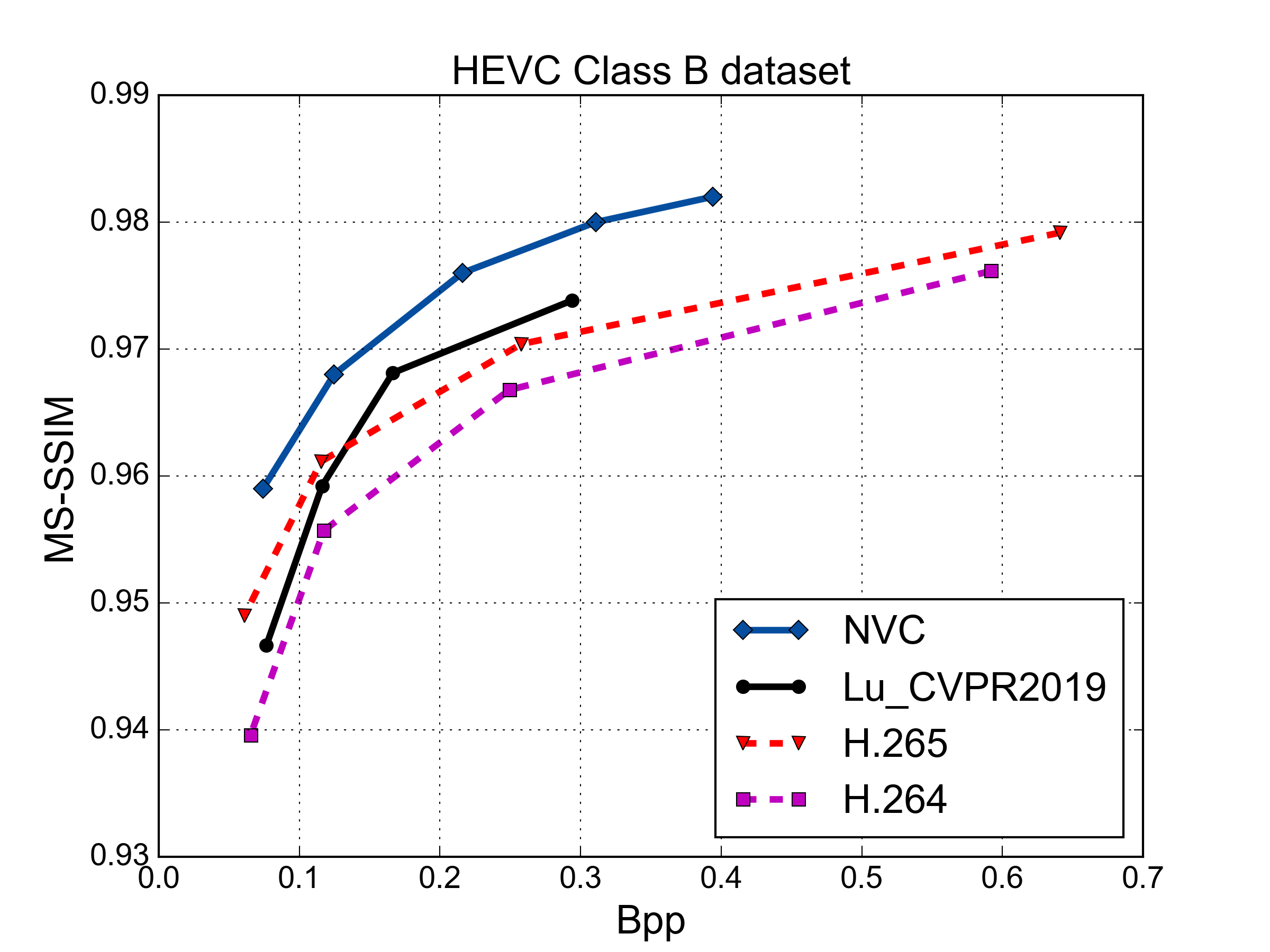
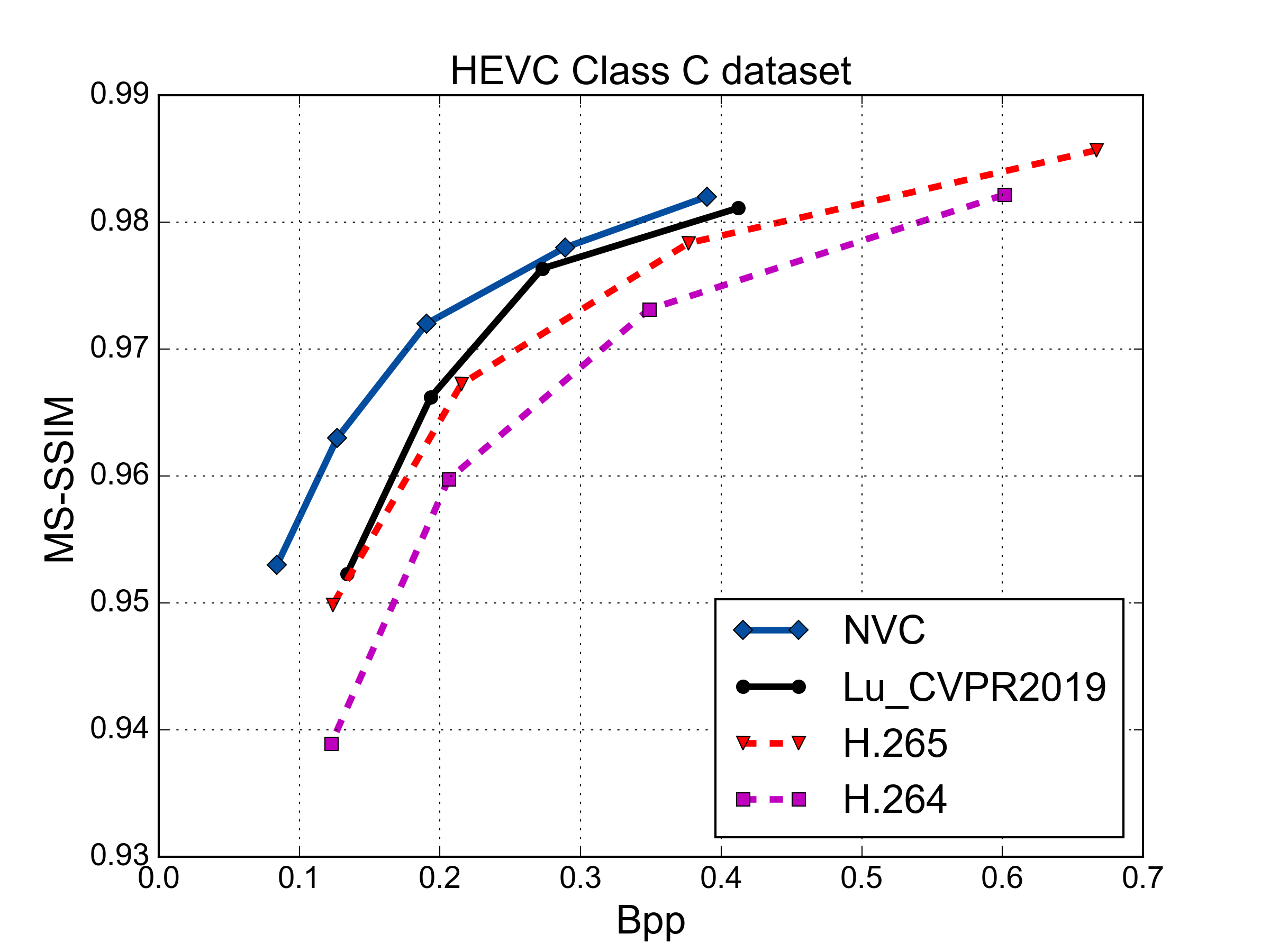
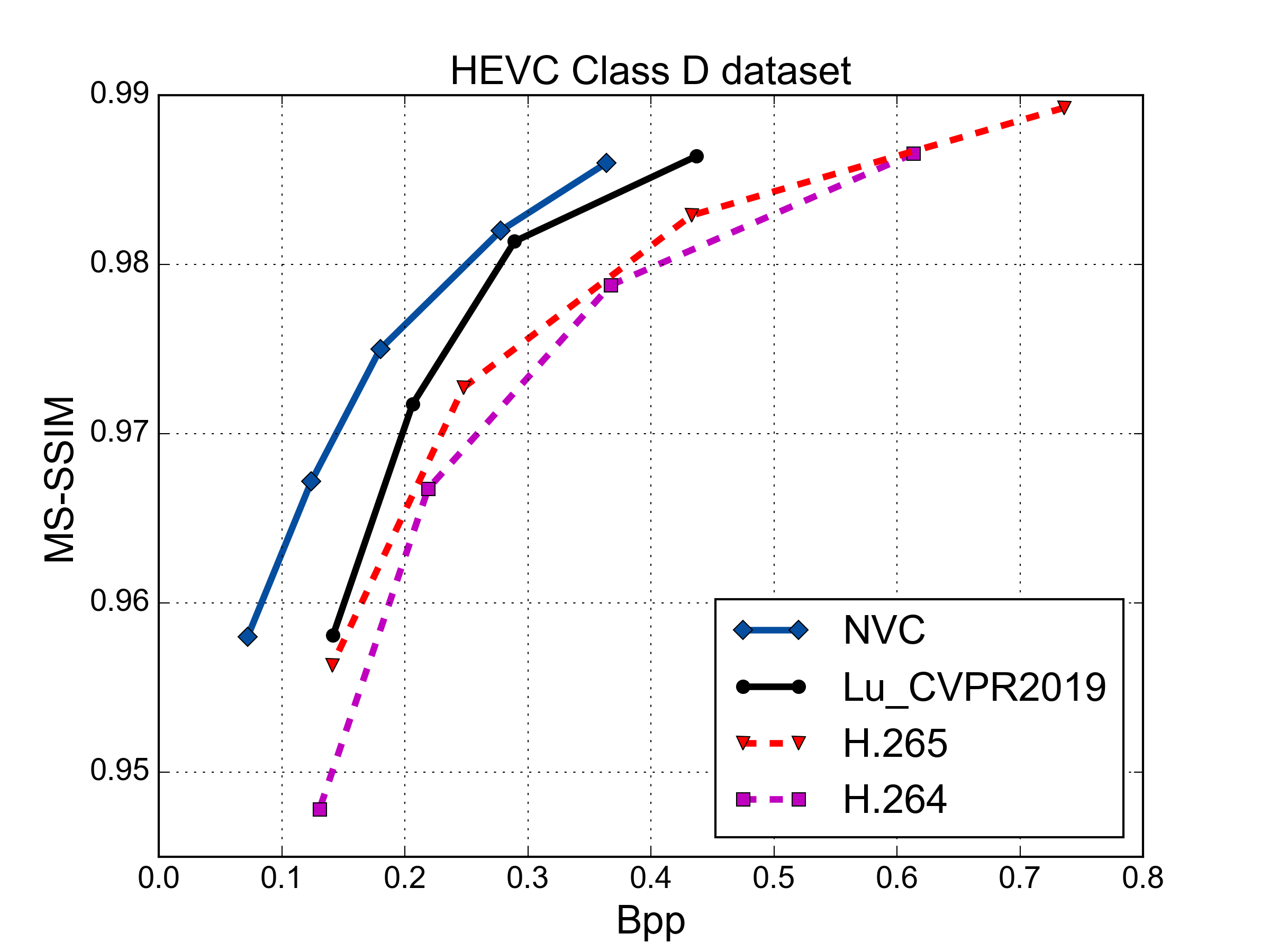
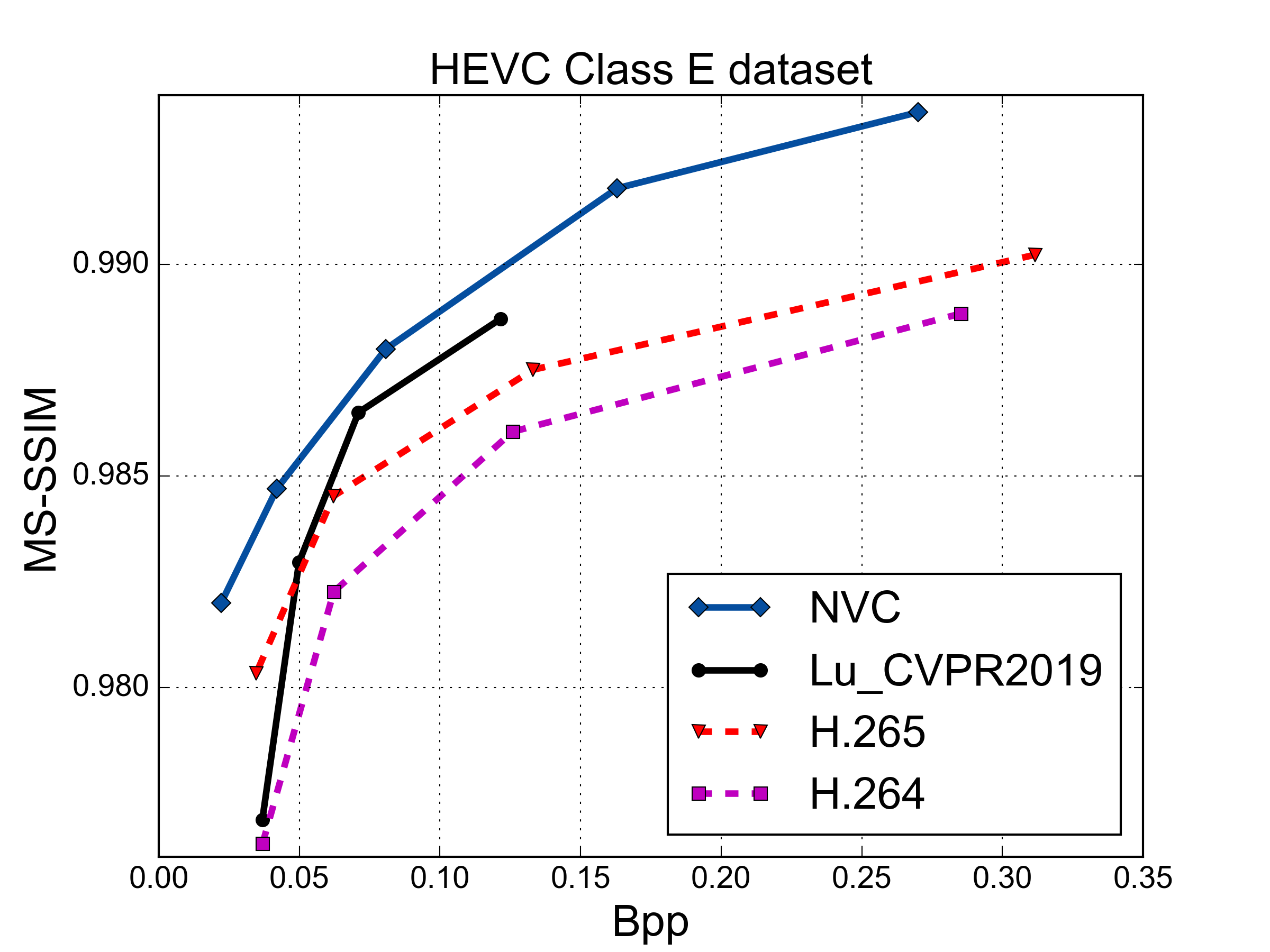
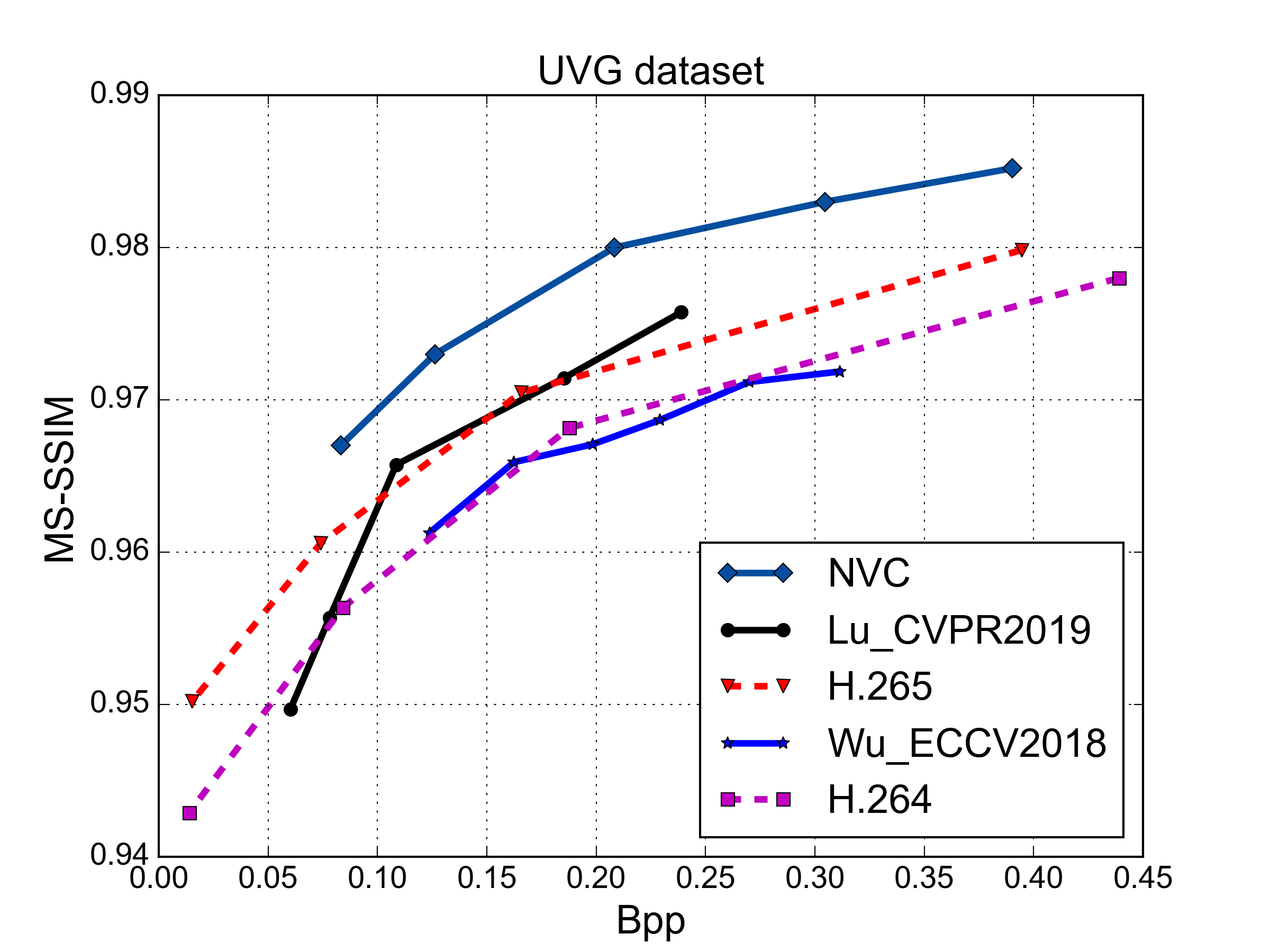
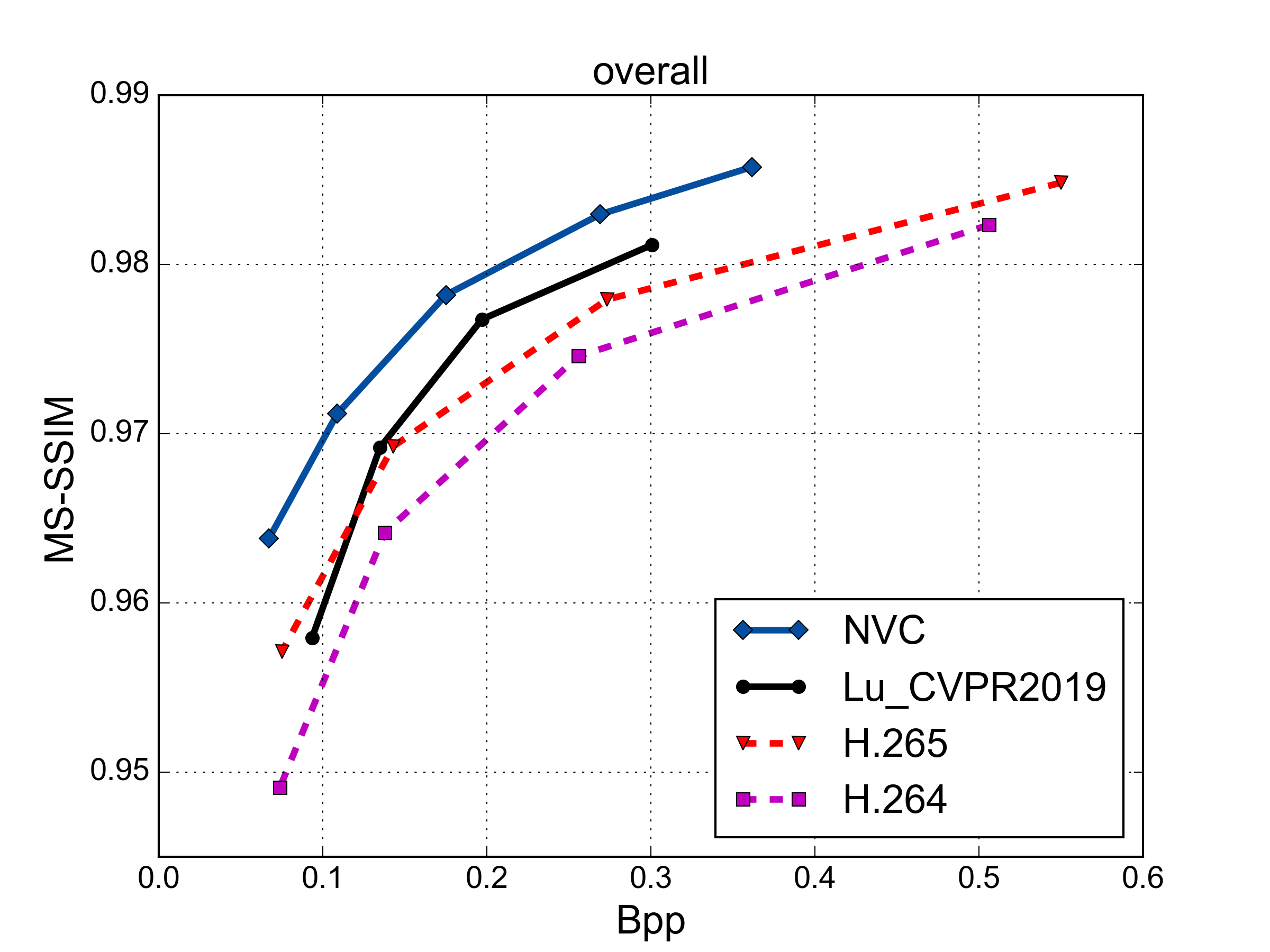
MS-SSIM vs. Rate Performance
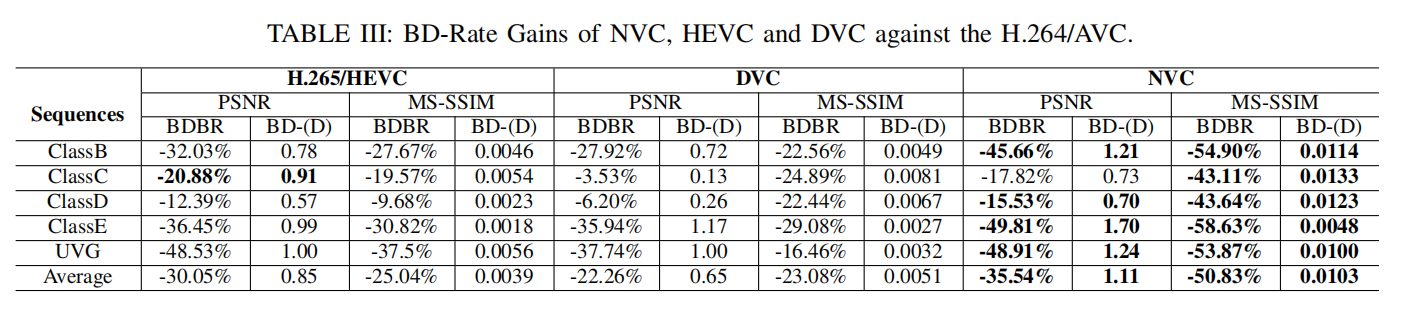
BD-Rate Reduction (PSNR & MS-SSIM)
Visual Comparison

Code and Model
The code and model will be released gradually.
b) Intra model (Outperform VVC).
d) Inter model (++ Spatiotemporal Context Model).
f) C++ implementation of seperate encoder and decoder using arithmetic coding.
Acknowledgement
More interseting works can be found in our NJU Vision LAB homepage.
Citation
If you find our paper useful, please cite:
Contact
You can contact Haojie Liu by sending mail to haojie@smail.nju.edu.cn