Abstract
The Object-Based Image Coding (OBIC) that was extensively studied about two decades ago, promised a vast application perspective for both ultra-low bitrate communication and high-level semantical content understanding, but it had rarely been used due to the inefficient compact representation of object with arbitrary shape. A fundamental issue behind is how to efficiently process the arbitrary-shaped objects at a fine granularity (e.g., feature element or pixel wise). To attack this, we have proposed to apply the element-wise masking and compression by devising an object segmentation network for image layer decomposition, and parallel convolution-based neural image compression networks to process masked foreground objects and background scene separately. All components are optimized in an end-to-end learning framework to intelligently weigh their (e.g., object and background) contributions for visually pleasant reconstruction. We have conducted comprehensive experiments to evaluate the performance on PASCAL VOC dataset at a very low bitrate scenario (e.g., ≲0.1 bits per pixel - bpp) which have demonstrated noticeable subjective quality improvement compared with JPEG2K, HEVC-based BPG and another learned image compression method.
Contributions
- End-to-end learnable framework for intelligent object-based compression by parallel processing masked image layers;
- Element-wise masking mechanism to support arbitrary-shaped object processing that leverages the advances in object segmentation and CNN-based image compression;
- Modularized functional components for supporting parallel processing and future extension (e.g., multiple image layers, different utility loss, substream extraction, etc)
Framework
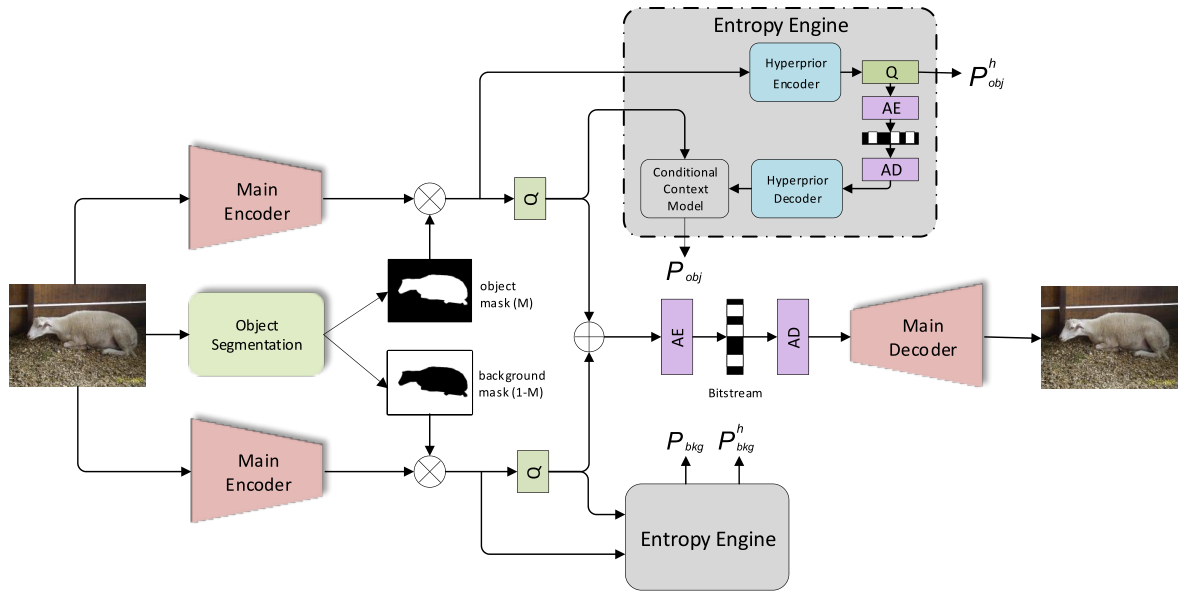 Fig.1. LearntOBIC. A two-layer structure is exemplified with upper part for object and lower part for background. Image segmentation uses the DeepLab with ResNet-34 as backbone, while a variational autoencoder (VAE) based NLAIC is used to process masked image layers in parallel. Q is for quantization, AE and AD are for respective arithmetic encoding and decoding.
Fig.1. LearntOBIC. A two-layer structure is exemplified with upper part for object and lower part for background. Image segmentation uses the DeepLab with ResNet-34 as backbone, while a variational autoencoder (VAE) based NLAIC is used to process masked image layers in parallel. Q is for quantization, AE and AD are for respective arithmetic encoding and decoding.
Experimental Results

 Fig.2. Visual comparison Reconstructed snapshots processed by JPEG2K, BPG, NLAIC and proposed LearntOBIC using PASCAL VOC 2012 and Kodak test images. Our method achieves significantly better subjective quality.
Fig.2. Visual comparison Reconstructed snapshots processed by JPEG2K, BPG, NLAIC and proposed LearntOBIC using PASCAL VOC 2012 and Kodak test images. Our method achieves significantly better subjective quality.
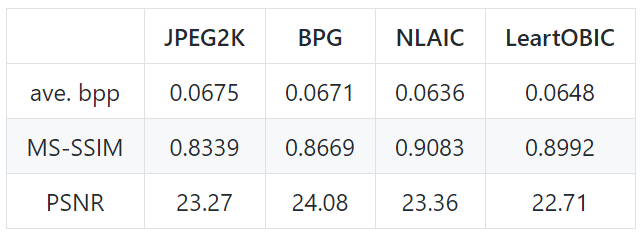
Table.1. Objective result on PASCAL VOC 2012 test set.
Resource
Code: Link
Paper: Available soon