NIC
End-to-End Learnt Image Compression via Non-Local Attention Optimization and Improved Context Modeling
1Vision Lab, Nanjing University
2New York University
Tong Chen1, Haojie Liu1, Zhan Ma1, Qiu Shen1, Xun Cao1 and Yao Wang2
Abstract
This paper proposes an end-to-end learnt lossy image compression approach which is built on top of the deep nerual network (DNN)-based variational auto-encoder (VAE) structure with Non-Local Attention optimization and Improved Context modeling (NLAIC). Our NLAIC 1) embeds non-local network operations as non-linear transforms in both main and hyper coders for deriving respective latent features and hyperpriors by exploiting both local and global correlations, 2) applies attention mechanism to generate implicit masks that are used to weigh the features for adaptive bit allocation, and 3) implements the improved conditional entropy modeling of latent features using joint 3D convolutional neural network (CNN) based autoregressive contexts and hyperpriors. Towards the practical application, additional enhancements are also introduced to speed up the computational processing (e.g., parallel 3D CNN-based context prediction), decrease the memory consumption (e.g., sparse non-local processing) and reduce the implementation complexity (e.g., a unified model for variable rates without re-training). The proposed model outperforms existing learnt and conventional (e.g., BPG, JPEG2000, JPEG) image compression methods, on both Kodak and Tecnick datasets with the state-of-the-art compression efficiency, for both PSNR and MS-SSIM distortion measurements.
Performance

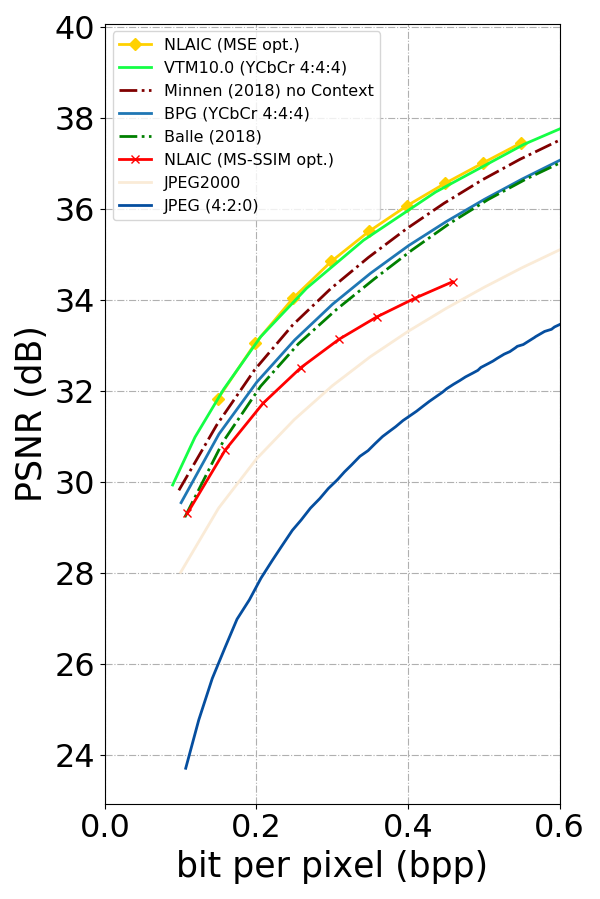
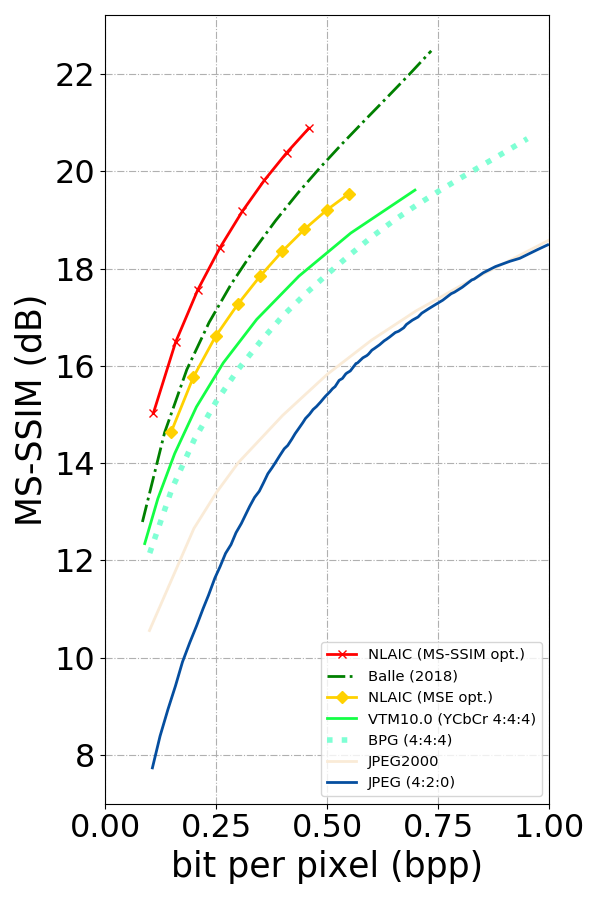
Materials
Citation
@ARTICLE{9359473,
author={Chen, Tong and Liu, Haojie and Ma, Zhan and Shen, Qiu and Cao, Xun and Wang, Yao},
journal={IEEE Transactions on Image Processing},
title={End-to-End Learnt Image Compression via Non-Local Attention Optimization and Improved Context Modeling},
year={2021},
volume={30},
number={},
pages={3179-3191},
doi={10.1109/TIP.2021.3058615}}
Acknowledgments
We are grateful for the constructive comments from anonymous reviewers. The corresponding author is Prof. Zhan Ma (mazhan@nju.edu.cn).